前一篇文章提出了一种可迭代,在不同抽象层中都具有自相似性的网络结构。这种解构中使用到了attention机制的相互作用、流形学习的度量距离修改赋予了远距离交互作用能力、平均场机制提供的pooling以及非线性激活函数、表征数值以及attention权重的二值离散化导致的信息压缩。理论上已经满足了信息瓶颈理论中必要的两个功能:熵减和非线性变换。
然而人工智能的很多其他特性并没有被解释,相变带来的后果也没有被讨论。这篇文章将会与更多交叉学科内的现象展开探讨,不仅限于深度学习以及物理方面。
社区结构community与小世界解构small-world
选取任意一阶的张量,之前“邻居”的定义是在query-key流形空间内,固定半径R以内的其他张量。先暂时不考虑非线性核的情况,那么半径R内的张量很容易相互构成邻居,形成社区解构community structure,如图中出现的黑色连接。
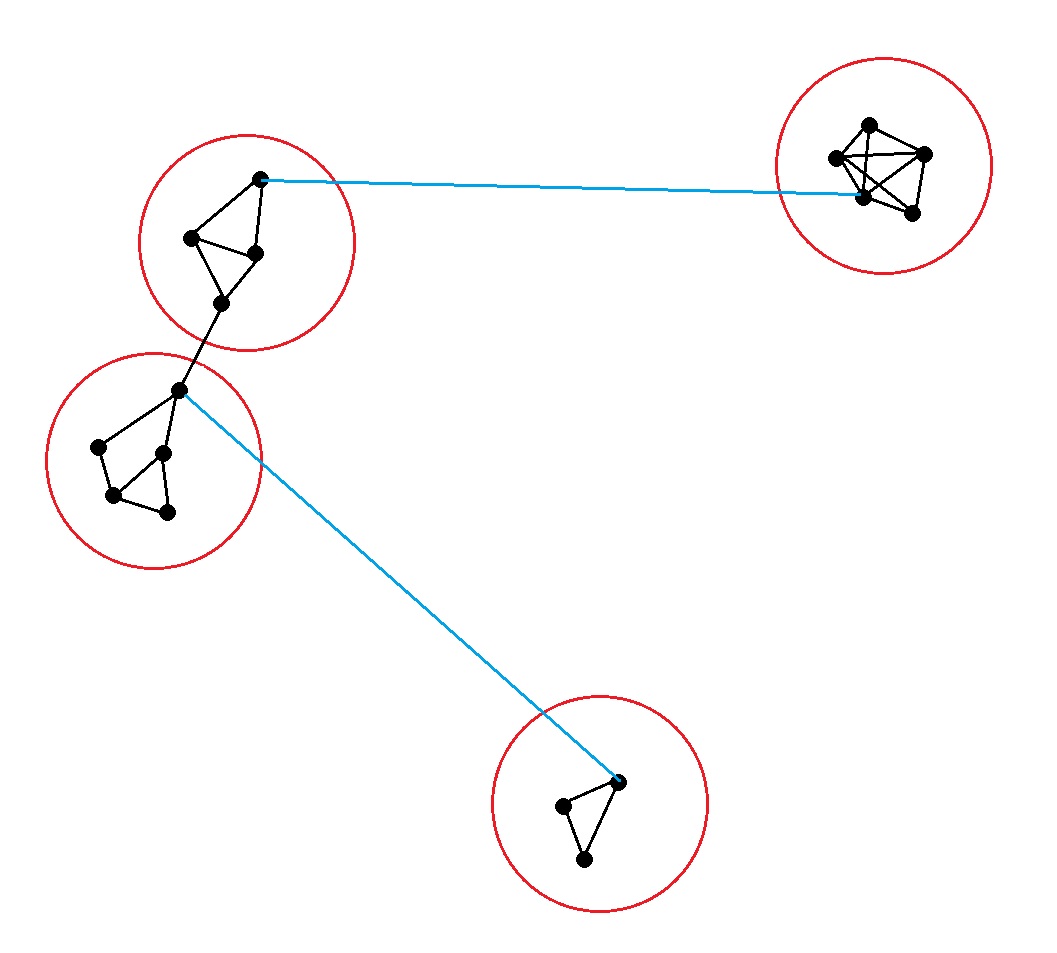
之后考虑非线性核在query-key流行内修改度量距离的情况,这时value空间内的远距离交互作用被允许,蓝色连接的距离被修改后也能满足半径门槛,所以一部分超过半径距离的蓝色连接也出现了。这种连接导致了small-world解构的出现。
当调整度量距离函数内的参数,使得曲率普遍小于1时,度量距离倾向于减小,创建更多的small-world连接,会使得原本几个分界明显的社区逐渐融合成一个大的社区。相反当曲率普遍大于1时,度量距离倾向于增加,一些原本的社区内部连接不满足距离门槛,社区内连接密度减少,逐渐退化成随机连接。
通过调整连接密度$\bar{n}$,我们可以控制平均场激活函数的形状,控制是否产生相变,以及产生相变时的非连续跳跃幅度。
![]()
![]()
到目前为止我们对距离的讨论仅限于相空间内的距离,以及流形变换后的度量距离,但实际上还有一种最底层的也是最无法忽视的距离,那就是神经元所在位置的物理空间距离。CNN中表现为像素坐标,RNN中表现为时间。
张量聚合时决定哪些低阶张量形成一个全新的高阶张量的规则,同时依赖于相空间距离以及物理空间距离。两种距离以一定比例混合,越靠近原始输入端,越低阶的聚合,越依赖于物理空间;越高阶靠近解码器一段的聚合,越依赖于相空间。这个很好理解,因为我们最终的输出肯定是依赖于相空间内的表征,在分类问题里每个抽象概念都代表了相空间内的一个独立维度。
“塔”中的相变雪崩
通过一层又一层的聚合迭代,我们的编码器是一个拥有金字塔解构的神经网络。起初所有张量,都处于相变区间的临界状态。
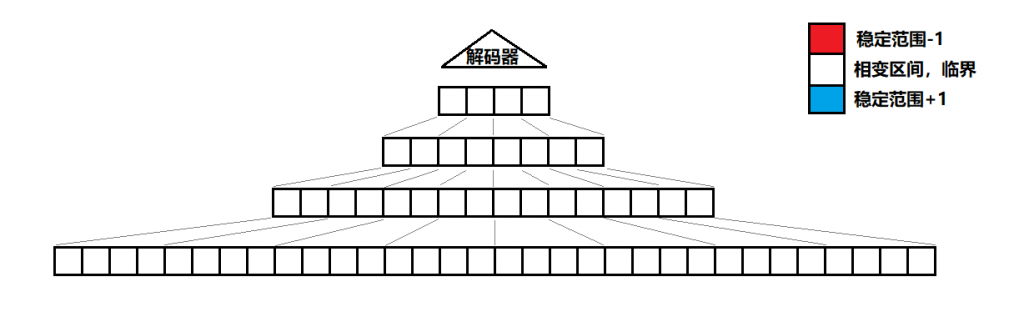
输入信号进入网络后,部分低层抽象概念的张量感受到较明显的输入信号,离开相变区间,进入到稳定范围。
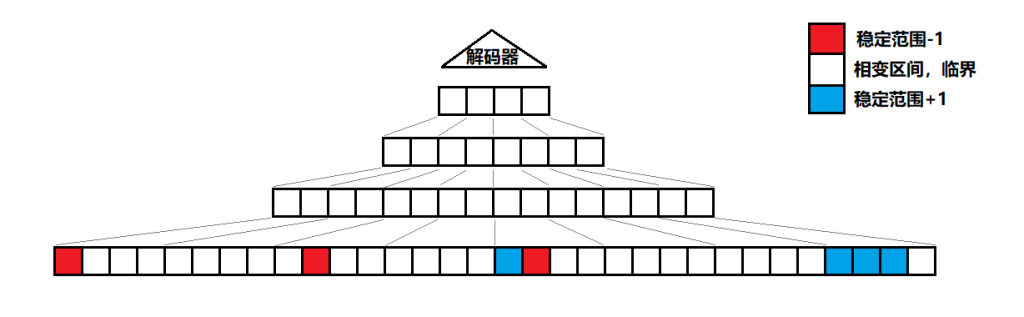
中层张量因为少量的输入信号改变,也被连锁反应引发相变,进入稳定范围。

最终相变如同雪崩一样传递至整个网络,且本来底层比较稀疏的信号,被正反馈的交互作用放大后,在高层更加密集。
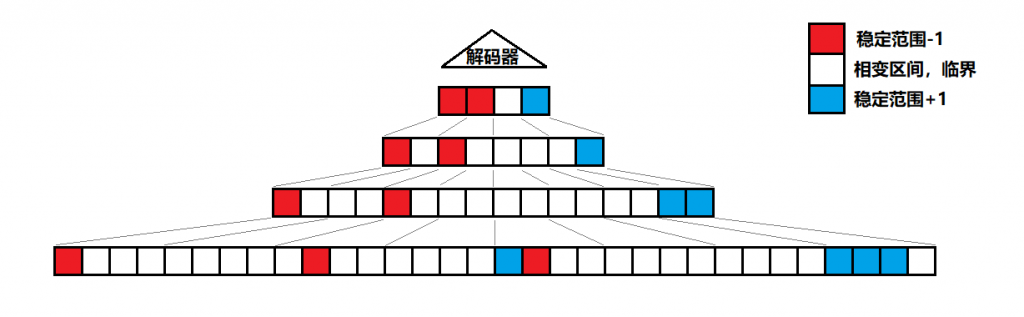
当然这样的全局雪崩并不一定每次都会发生,如果张量收到的输入$B_{ext}$没有强到足够脱离相变区间,那么无论是+1还是-1的信号,都会逐渐归零。或许会在归零之前累积一些$B_{ext}$中的bias,使得下次相同方向的信号触发相变能更容易一些。
如果不刻意调整每个张量的$\bar{n}$,固定每个张量的相变区间,雪崩的波及到的张量数量与频率应该如同沙堆模型一样呈现出某种幂律关系。然而“学习”的过程,显然需要通过调整社区内的连接密度,尽量让大部分张量能够随时处于相变范围内,或是离相变门槛非常接近的地方,称之为“混沌边缘”。所以幂律关系并不会如同自然界中最经常呈现出的样子。
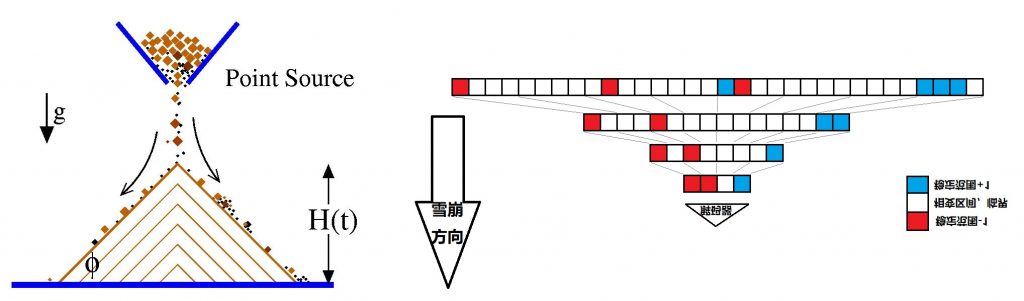
每次“雪崩”都会导致自组织的熵减,根据信息瓶颈的定义,熵减的过程正是学习重要的信息,同时遗忘不重要的噪音的过程。通过调整$\bar{n}$让雪崩更频繁地发生,或是以更大波及规模的发生,都是在加速学习的过程。让有限次的输入信号刺激,尽量多地引发相变,才是人脑使用少量样本学习的关键。在沙堆模型中,你很难指望下落的每一粒砂都能引发雪崩,除非你有能力调整地面坡度的角度、沙堆的内部结构,或是摩擦力系数之类的关键数值。
熵减与学习
如果不考虑远距离信号传递,那么信号的最短路径,就是从直属的children张量内使用平均场计算出标量输出。然而如果考虑“small-world”结构带来的同级信号的远距离传输,那么目标张量是可以受到不同信号路径来源的影响的。当信号传递的速度被考虑进来后,不同路径长度也就带来了不同的信号到达时间。前面的文章内都假设了每一层信号在传递给更高层之前,都有充足的时间通过磁针交互作用形成稳态,然而真实情况下很多信号来不及经过交互作用的修正,就直接被聚合,传递给更高层了。换言之self-attention应该被视作一个动态的过程,而非一个最终到达了热平衡的状态。
沙堆模型雪崩停止之前的动力学传播过程,就可以类比于上面的ising模型动力学。两者都可以看作是某种元胞自动机,因为两个模型都使用到了一些离散化的思想,同时整个系统的状态随时间演化。
将外部信号$B_{ext}$加入时间变量变成$B_{ext}(t)$后,平均场输出$\bar{s}(t) = \sigma(B_{ext}(t))$也同样随时间改变了。输出在最终稳定下来之前,可能在磁滞回线-1和+1的两端来回往返跳动若干次。
在具有铁磁性的材料中,磁滞回线中间围成的面积就是每次$B_{ext}(t)$完成一次相变改变周期时损失的能量,能量会以废热的形式耗散到周围环境。假设整个系统是恒温的,例如人体体温37度,那么$T=\frac{dU}{dS}$意味着正比于磁滞回线耗散能量$U$的熵$S$也从张量转移到了周围环境中,张量获得了负熵,信息被压缩。大张量嵌套了小张量,由于自相似性,我们将整个网络视作一个最大的张量,则整个系统也是熵减的。
熵减的过程是自发的,且是不可逆的,输入信号在变更底层磁针方向时带来了信息,也输入了能量。调整社区结构内连接密度也需要能量的输入,这些能量都会在相变雪崩时被耗散到周围环境中。系统需要不断补充与消耗能量,可以看作是开放系统。
“智能体以负熵为食,维持自身的低熵状态”
记忆?自由意志?梦境?
决定一个张量是否被激活,往哪个方向激活的输入,在前一篇文章内被定义为了
$B_{ext}=\frac{1}{|H_i^{(l)}|}\sum\limits_{m \in H_i^{(l)}} f(H_{m}^{(l-1)}) + b$
大致由sum以及bias两个部分组成,sum可以看作是直接输入的信息,在低阶张量内的平均场标量表征的平均值,bias是一个偏置。
常识告诉我们一个人感受到的信息,不光取决于输入,还取决于他的经验、记忆。bias就是一个能够在输入信号到来之前,预先有方向选择性地改变相变门槛的一个功能。它能让张量在被输入信息之前就处于待激活、常开,或是常关的状态。不同张量的不同bias,可以看作是一个人的记忆施加在认知推理过程中的影响。计算机中记忆是通过一些特定组合的“门”内电流信号不断循环形成的,人脑中海马体内也可以存在类似的功能,然后与不同抽象等级上的不同张量对应的区域通过某种远程传导机制施加一个常态化的影响,形成一个或是增强或是抵消输入信号的bias。
所谓自由意志,可以理解为人类可以通过认知系统以外的决策系统,产生一些信号,用来强制修改认知系统内的一些张量的bias,由此达到与记忆类似的相变修正效果。这种效果是临时的,当然如果自我暗示久了也不排除会影响到记忆系统的可能性。
大脑维持临界状态,实际上就是通过修改每个张量的神经元连接密度$\bar{n}$,使得在没有信号输入时,大部分张量都能维持在考虑了bias之后能随时因为很小的输入扰动也能发生相变的状态。
睡眠时,短期记忆会写入长期记忆,bias会发生调整,具体调整方法和机制,需要对记忆模块有更深的研究。但很明显当bias变化时,就如同模拟了一些输入信号一样,张量“塔”内也可能会发生相变雪崩,这种并非因为真正信号输入,而因为bias改变导致的雪崩,就是做梦。
编码器vs解码器
当$\beta \bar{n} J > 1$时会产生相变,但是不同大小的$\bar{n}$与磁滞回线面积仍然有很大区别。较小的$\bar{n}$拥有较小的相变门槛,同时磁滞回线面积较小;反之当$\bar{n}$较大时相变门槛与磁滞回线面积。前者更适合用于推理不确定的因果关系,后者更适合已经形成固化习惯的,接近于本能的推断。原因有以下几个:
- 从效能的角度分析,不确定推理考虑到的不同路径的信号,发生冲突的概率较大,因此$B_{ext}(t)$的信号部分的均值变化幅度小且频率高。这样较小$\bar{n}$的相变更加灵活,且每次周期相变损失的能量也较小。长时间思考就不消耗太多能量了。
- 低密度社区在经过频繁的推理与两个方向的激活后,连接密度逐渐增加,扩大磁滞回线面积,这种变化符合了“用进废退”的神经元连接机制。
- 已经形成习惯的张量,接收到的低等级输入信号也普遍饱和,且不太可能发生冲突,所以激活相变的门槛虽然高,但也不难满足。一旦被激活,就会输出确信度非常高的接近于饱和的平均场信号。高$\bar{n}$的张量让经过它的信号更加保真。
- 如果采纳前面的关于“记忆”与“自由意志”的描述,那么bias的偏置量应该是有限的,所以他们能够起到较大影响作用的地方,只存在于较小$\bar{n}$的张量,即高抽象等级的概念里。在趋近于“本能”的概念张量内,一个不大的偏置量仍然无法抛开输入信号的影响,直接让张量获得激活。
- 高$\bar{n}$张量的输出不容易随时间发生震荡,可以迅速收敛推理,符合对于“本能”的需求。低$\bar{n}$因为输出信号震荡的关系,收敛较慢,所以不常用的、高抽象等级的张量,进行相关推理往往需要耗费更长时间。
- 当$\bar{n}$小于1时,网络的表现类似于现在的全连接解码器,信息压缩能力进一步减弱。这也符合现在深度学习框架内编码器负责压缩信息,解码器负责生成内容的思路。所以一个连续的,随着抽象等级不断提升,社区内连接密度不断下降的网络结构,从功能上比起无规律的$\bar{n}$更能满足要求。
当然在信号到达解码器的终点之前,还需要经过决策系统。决策系统是怎样产生reward,并动态调整强化学习中的值函数,与认知系统的关联性不那么紧密,这里也不做过多讨论了。
结语
经过一系列定性的论证,我们已经将第一篇文章内的疑问大部分进行了解答。实验设计比较麻烦,但即使不做实验,也已经从理论上做出了足够多的预测,且与很多已知的现象和经验吻合。更多对于复杂系统以及海马体记忆的研究需要被进行,如果没有一个正确的调整bias的机制,网络很难学到有用的知识。仅靠调整神经元之间是否产生链接,并无法完成针对记忆系统的写入和读取。
