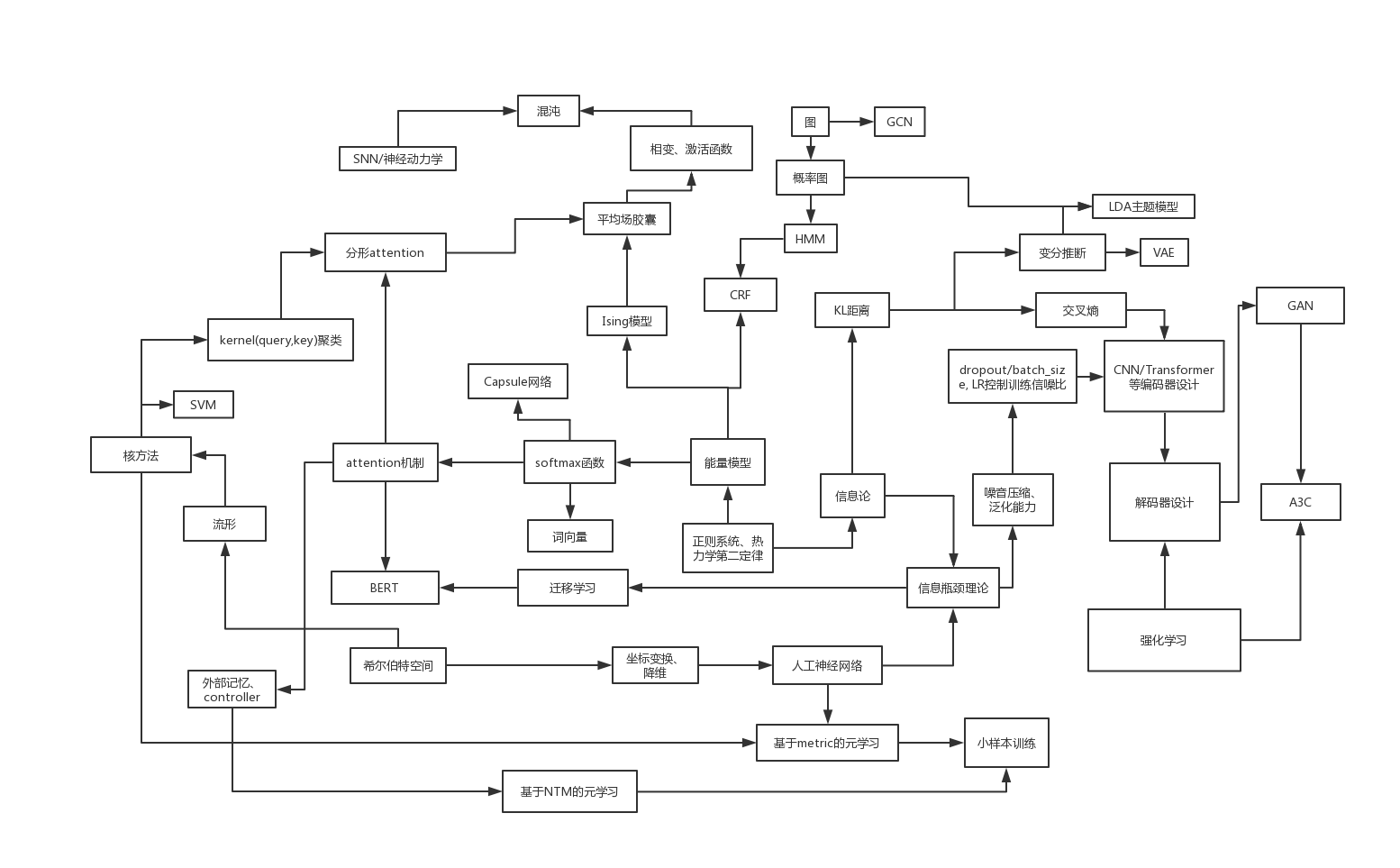
深度学习体系综述:
- 热力统计学的一系列限制条件,推导出能量模型Boltamann分布,进而构建起了大部分DL模型的分类选择功能。
- 相空间的非线性变换,是所有编码器的两个刚需功能之一。非线性变换主要有两种实现方法,一是线性变换+非线性激活函数,二是直接修改测地线度量距离,也就是使用核方法。第一种方法直接指定了变换后的维数,欠缺灵活性;而第二种产生的流形,理论上可以内嵌在任意维的相空间内,只要在任意一个相空间内该流形各点的曲率都是0,那么就完成了从原空间到新空间的非线性变换。
- 编码器另一个刚需是信息压缩。由中心极限定理在有限数据集内可推导出泛化误差上界的不等式,要提升模型的泛化能力就必须缩减假设空间的大小。热力统计学定义的熵正比于假设空间大小的对数,与微分熵相差了一个常量,所以提升泛化能力必然意味着信息压缩。信息压缩的方法包含了降维、dropout、离散化、使用带噪音的梯度更新,以及一些其他方法。
- 监督学习由于设置了监督目标,从而将目标的信息引入了模型中,与信息压缩形成了对冲。于是信息瓶颈方法构成了所有监督学习的通用规则。目标信息的增加与噪音信息的压缩可以以不同的顺序发生,也可以同时发生但以不同的比例混合在一起。
- 元学习、迁移学习、小样本训练、多目标监督,甚至于多模态监督(的部分思想)的本质都是同一个,即使用与目标训练集相似的数据集,例如预训练数据集,首先进行初步的信息压缩,剔除掉大部分不合格的想象空间,保留那些通用性较高的想象空间,这样在使用目标训练集的时候,想象空间就已经被限制在了一个较小的范围内,从而获取一定泛化能力所需的样本数量也可以相应减少。
- 变分推断、交叉熵,本质上也都是在进行信息瓶颈的操作,变分推断主要目标在于寻找不同样本之间信息的“最大公约数”,交叉熵则是通过KL距离让隐藏层表征的信息不断趋近于监督目标的信息。
- 外部记忆(NTM)-内部记忆(LSTM),本质区别只在于每次记忆更新是全部更新,还是只更新记忆的一部分。每次只更新一部分的记忆比全部更新要拥有更长的信息保存时间,但也更难收敛。多头外部记忆可以看作介于外部与内部之间的一种平衡的记忆。
- 解码器一般不需要信息压缩,直接非线性变换就好。
- 决策系统所需的强化学习,总是在用各种方法优化Bellman方程。考虑到一般Bellman方程涉及到的步数都比较长,在值函数的评估上引入外部记忆或许能有较大性能提升。
- 感知-编码器,记忆-NTM/LSTM,决策-强化学习,控制-解码器。最难也是最神秘的就是认知功能了。已知认知网络需要具备某些分形的具有自相似性的网络结构,信号在经过感知器压缩编码处理后,以低熵甚至是离散化的形式输入。抽象等级随着分形内的社区结构聚合而提升,又因为每层抽象等级都需要与记忆模块相连,导致不同层的输入与输出必须满足自相似。基于Ising模型以及self-attention机制,我提出了一种满足上述需求的网络结构。并且能够推测出该结构允许存在类似于沙堆模型的自组织临界状态,从而得出认知模块与前面连接的感知模块一起,构成了一个耗散结构,需要用复杂系统相关的知识来进行分析。结构的一些其他特性也符合了认知科学中对于人脑的很多观测。其中也包括用Ising模型来解释非线性激活函数产生的原理。
总之,可以通过底层数学与物理原理,看到深度学习体系与传统机器学习的诸多流派能够形成统一,与认知科学以及人类行为常识也越来越能够被纳入到一个理论框架下。
